
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- pytorch
- elif
- python practice
- sigmoid
- Attention
- word2vec
- overfitting
- XOR
- sentence embedding
- abstraction
- Self-loop attention
- NLP
- Transformer
- GNN
- deep learning
- neural net
- Set Transformer
- Python
- Classificaion
- machine learning
- Today
- Total
Research Notes
[DL] Neural Network - ReLU and Weight Initialization 본문
▶ ReLU의 출현
- 신경망의 층이 깊을때, Backpropagation을 사용하였을 경우 학습이 잘 안됨 : Vanishing Gradient(경사 감소 소멸)
- sigmoid의 잘못된 사용

▶ReLU : Rectified Linear Unit
- ReLU 함수 : x가 0보다 크면 y=x, x가 0보다 작으면 0
▶ 다양한 Activation Functions
- sigmoid, tanh, ReLU, Leaky ReLU, Maxout, ELU 등 여러 가지의 활성화함수가 존재
▶ Weight 초기값 정하기
- Vanishing Gradient를 해결할 수 있는 방법
1) ReLU 함수의 사용
2) Weight의 초기값을 잘 정하기
- 초기값을 줄 때 주의점
· 값에 0을 주면 안됨
· RBM(Restricted Boatman Machine)을 사용하여 가중치 초기화를 시키는 네트워크를 사용할수도 있다.
▶ RBM(Restricted Boatman Machine)
- 2개의 레이어만 사용하여 encoder, decoder를 반복하여 pre-training을 함.
1. 처음의 두 레이어를 입력값과 유사하게 학습을 시킨다.
2. 그 다음의 두 레이어 학습
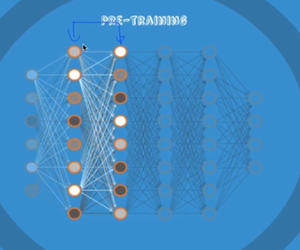
3. 그 다음의 두 레이어 학습

4. 실제 학습 데이터를 사용하여 마지막 학습 ; Fine Tuning
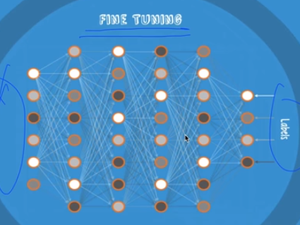
- RBM은 처음에는 획기적이었으나 복잡하였음.
▶Xavier Initialization
- 입력값(fan_in)과 출력값(fan_out)에 따라서 W을 랜덤하게 줌. (아래와 같은 방식)
# Tensorflow
W = np.random.randn(fan_in, fan_out)/np.squrt(fan_in)
# 2015 오류 개선
W = np.random.randn(fan_int, fan_out)/np.sqrt(fan_in/2)- 이러한 형태로 주면 RBM과 유사한 성능을 낼 수 있다고 밝혀짐.
'Study > Deep Learning' 카테고리의 다른 글
| [DL] Convolutional Neural Networks (CNN) (0) | 2023.07.03 |
|---|---|
| [DL] Neural Network - Dropout and Model Ensemble (0) | 2023.07.03 |
| [DL] Neural Network - XOR Problem, Back-propagation (0) | 2023.07.03 |
| [DL] Basic Concept of Deep Learning (0) | 2023.07.03 |
| [DL] Skip-Thought Vectors (0) | 2022.09.21 |



