
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- abstraction
- GNN
- Classificaion
- Self-loop attention
- deep learning
- elif
- Transformer
- neural net
- sigmoid
- Attention
- XOR
- python practice
- Set Transformer
- overfitting
- Python
- machine learning
- word2vec
- pytorch
- NLP
- sentence embedding
- Today
- Total
Research Notes
[DL] Attention 본문
< 목차 >
1. Key, Query, Value
2. Self-Attention
3. Attention in Transformer
1. Key, Query, Value
Key(K), Query(Q), Value(V)는 Attention의 핵심 키워드. Key, Query, Value의 특징은 아래와 같음
- Dictionary 자료 구조이므로, Query와 Key가 일치하면 Value를 리턴함
- Dictionary 자료형의 결과 리턴 과정 (attention score를 계산하는 과정과 유사)
- 1) key와 value의 유사도를 계산
- 2) 유사도와 value를 곱함
- 3) 유사도와 value를 곱한 값의 합을 리턴
K, Q, V가 Attention에서는 어떻게 사용될까?
- Attention이란, query와 key의 유사도를 계산한 후, value의 가중합을 구하는 과정임
- Attention score란 value에 곱해지는 가중치
- k, q, v는 vector(matrix) 형태이고, similarity를 계산하는 함수가 중요함

- Similarity Function (Alignment model)은 다양하게 구현될 수 있음 (아래 그림)

2. Self-Attention
Feature를 표현할 때, 기존 RNN과 CNN 기반 네트워크들의 한계로 Attention의 개념이 도입되었다.
- RNN의 한계
- Sequence한 데이터가 입력되어, 앞 Sequence에 입력되었던 값들의 의미가 희석됨
- 계산 시간이 오래 걸리고, 복잡도가 높아짐
- Grandinet Vanishing, Long term dependency 문제 발생
- CNN의 한계
- CNN은 Window size에 대해서 feature representation을 학습함. 따라서 window size 외의 값들은 해당 hidden state의 연산에 반영할 수 없음
- Long path length between long-range dependencies 문제 발생
- Self-Attention이란? RNN, CNN 구조를 사용하지 않고 attention만을 사용하여 feature를 representation하는 것
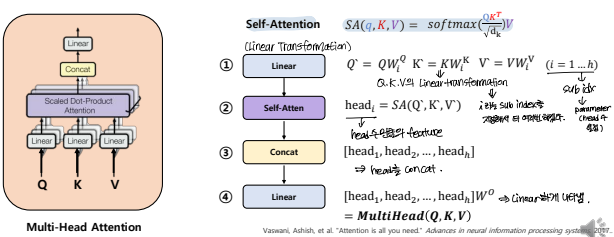
- K, Q, V는 word embedding vector의 hidden state가 됨
- scaled-dot product로 similarity를 계산함
- multi-head attention -> 여러 번(head의 수 만큼)의 experiment를 진행함
- Transformer에서 사용하는 Attention 개념
3. Attention in Transformer
Transformer는 아래 그림과 같은 구조를 가짐. Transformer에서 Attention이 어떻게 작동하는지 설명하고자 함
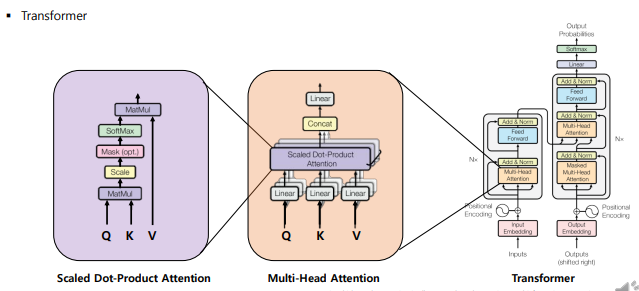
Transformer에서 Scaled-Dot Product Attention는 Self-Attention을 의미한다.
- K=Q=V=word embedding vector의 hidden state(X)
- Similarity function=Dot-product을 통해 계산함
< Scaled Dot Product Attention 과정 >

< Multi-Head Attention 과정 >
위의 Scaled Dot Product와 동일하지만, head의 수(h, parameter)만큼 Attention score를 여러번 반복하여 계산한다는 것이 차이점임
Transformer에서 Attention의 Contribution
- computational complexity가 줄어듦
- 병렬 처리가 가능
- long term dependencies, long-range dependencies 문제 해결
- interpretable models
- head의 수만큼 attention score를 시각화할 수 있음
- 모델이 어느 부분에 attention을 해서 학습했는지 표현할 수 있기 때문에 explainable한 모델을 설계할 수 있음
'Study > Deep Learning' 카테고리의 다른 글
| [DL] Basic Concept of Deep Learning (0) | 2023.07.03 |
|---|---|
| [DL] Skip-Thought Vectors (0) | 2022.09.21 |
| [DL] Sent2Vec (Sentence2Vec) (1) | 2022.09.21 |
| [DL] Word2vec (0) | 2022.09.21 |
| [DL] Graph Neural Networks (0) | 2022.04.02 |


