
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- deep learning
- python practice
- Set Transformer
- Attention
- sigmoid
- Classificaion
- sentence embedding
- Self-loop attention
- word2vec
- GNN
- Python
- NLP
- neural net
- pytorch
- abstraction
- Transformer
- machine learning
- overfitting
- XOR
- elif
- Today
- Total
Research Notes
[R] Data Mining: Classification Rules and Overfitting 본문
[R] Data Mining: Classification Rules and Overfitting
jiachoi 2023. 7. 3. 11:541. 데이터마이닝과 분류
▶ 분류 (Classification) : 다수의 속성을 갖는 객체를 그룹 또는 범주로 분류하는 것
학습 표본으로부터 효율적인 분류규칙을 생성(=오분류율 최소화)
▶ 분류규칙 예시
1) 임의로 분류규칙 선정

2) 오분류율 제시
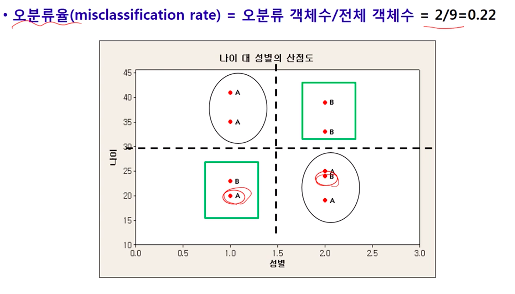
3) 두번째 분류규칙 제시(더 자세하게)

2. 과적합(overfitting) : 모델이 너무 데이터화된 경우.
- 분류모형에서 훈련데이터에 대한 과적합을 시킬 경우, 실제 데이터를 적용했을 때 더 높은 오분류율 발생.
- 실제 데이터가 들어갔을 때 정확도가 낮아지는 문제 발생.
- 이를 해결하기 위해 학습데이터와 검증 데이터를 나눠서 모델의 성능을 학습시키며 평가

▶ 교차검증 : 분류모형의 유효성 검증 방법
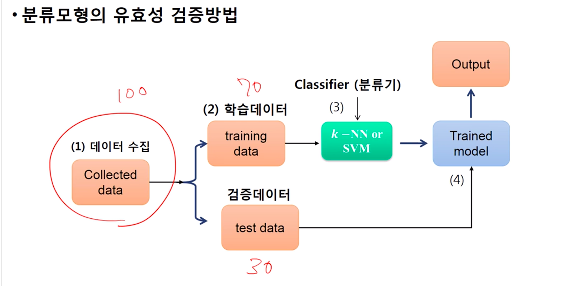
▶ K-fold cross validation method : 교차타당성 검증
- n=100이면 5등분으로 나누어 4등분은 학습데이터로 예측모형을 구성하고 나머지는 5등분째 데이터로 검증.

3. 학습데이터와 검증데이터
▶ Iris 데이터를 통한 분류분석의 예제
- 꽃잎의 폭과 길이에 대한 4개 변수로 꽃의 종류를 예측하는것이 목적
- 타겟변수(y) : setosa, versicolor, virginica
# set working directory
setwd("/Users/choijia/postech_ai/ML/Week_9-4")
# read csv file
iris<-read.csv(file="iris.csv")
head(iris)
str(iris) # 데이터의 특성
attach(iris)
Sepal.Length~Petal.Width : 독립변수, Species : 종속변수

# training/ test data : n=150
set.seed(1000, sample.kind="Rounding")
N=nrow(iris)
tr.idx=sample(1:N, size=N*2/3, replace=FALSE)
tr.idx- set.seed(1000) : 데이터를 랜덤하게 난수화. 처음 시작값을 주어 동일한 훈련표본 사용.
# attributes in training and test : ~열의 종속변수를 제외한 100개의 데이터 / 50개의 데이터
iris.train<-iris[tr.idx,-5]
iris.test<-iris[-tr.idx,-5]
# target value in training and test
trainLabels<-iris[tr.idx,5]
testLabels<-iris[-tr.idx,5]
# to get frequency of class in test set
table(testLabels)
'Programming Language > R' 카테고리의 다른 글
| [R] Support Vector Machine (SVM) (0) | 2023.07.03 |
|---|---|
| [R] Discriminant Analysis (0) | 2023.07.03 |
| [R] K-Nearest Neighbor (KNN) (0) | 2023.07.03 |
| [R] Data Mining: Multiple Linear Regression (0) | 2023.07.03 |



